![]()
Mesh
Polygon Mesh Primitives >
Cylinder
| Toolbar | Menu |
|---|---|
|
|
Mesh Polygon Mesh Primitives > Cylinder |
The MeshCylinder command draws a polygon mesh cylinder.
| Command-line options | |
|---|---|
|
Direction |
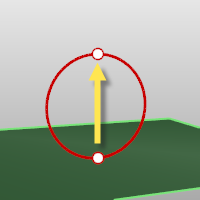
Direction constraints restrict the direction of the circle. NoneThe center can be anywhere in 3-D space.
VerticalDraws an object perpendicular to the construction plane.
AroundCurveDraws a circle perpendicular to a curve. |
|
Solid |
Fills the base with a surface to form a closed solid. |
|
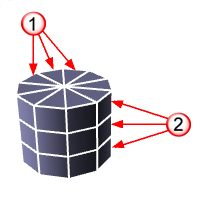
AroundFaces |
AroundFaces (1)The number of faces around the circumference. VerticalFaces (2)The number of faces from the base to the apex. |
Draw a cylinder.
Create a mesh from a NURBS surface or polysurface.
Rhino for Mac © 2010-2017 Robert McNeel & Associates. 24-Oct-2017